Research Interests
My research interests are at the intersection of security, privacy, AI. Specifically, most of our research aims at improving the trustworthiness and safety of generative AI systems, as well as investigating the application of AI in enhancing security measures, like vulnerability discovery, static and dynmaic analysis. Recently, my primary research interests are as follows.
1. AI Security and Privacy.
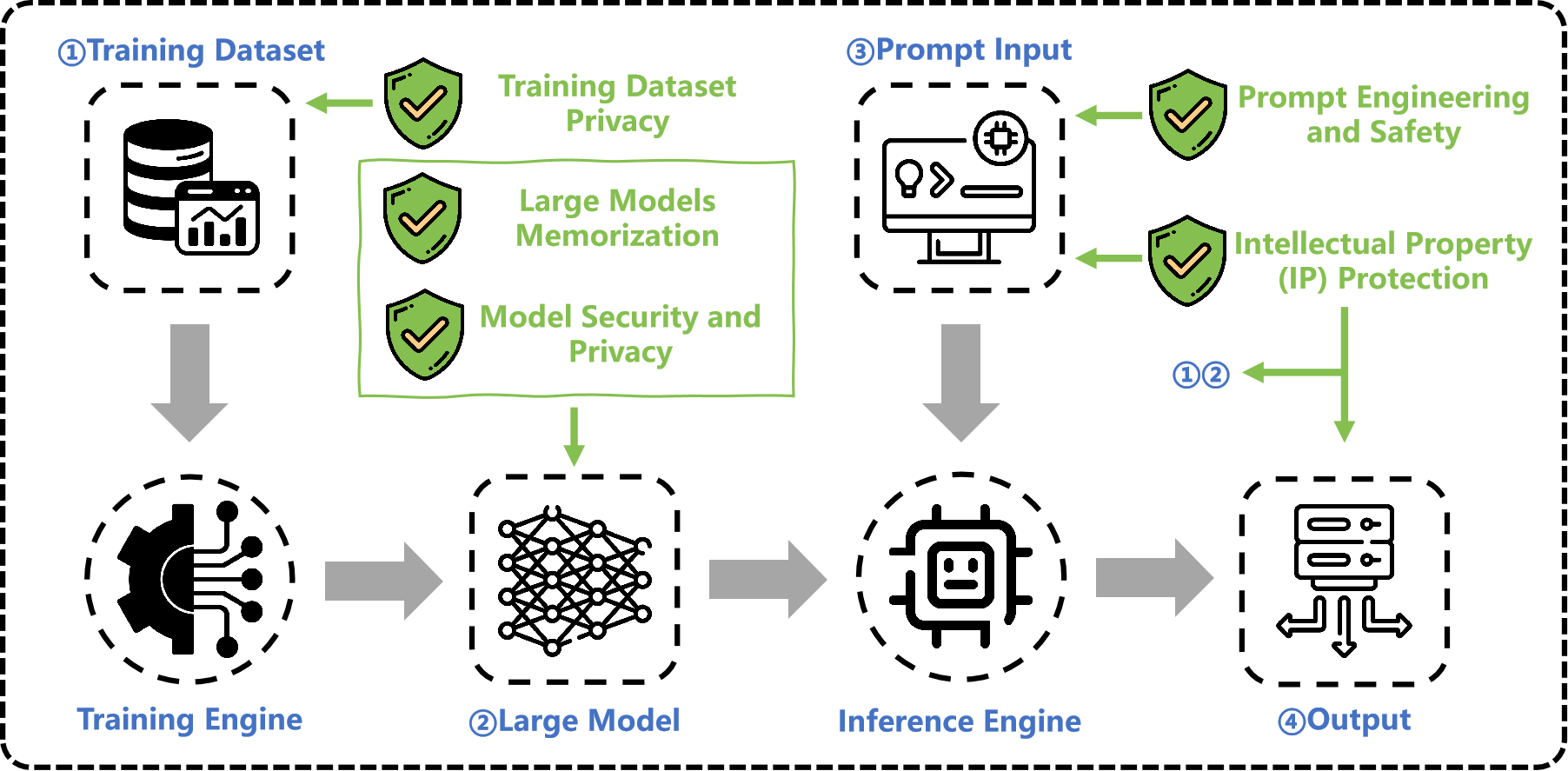
The rapid advancement of large models has transformed the AI landscape, leading to a wide array of applications in real-world scenarios. However, this progress has also revealed significant security and privacy concerns, including unintended system behaviors, privacy breaches, and the spread of harmful information. Our objective is to investigate these security vulnerabilities and develop defense solutions to create trustworthy and responsible AI system. Recently, we have focused on LLM-based and VLM-based agents to examine vulnerabilities and explore defenses against various potential threats, such as jailbreaking and prompt injection. These agents are being deployed in safety-critical domains, reflecting the growing use of large model-powered agents across diverse applications.
• Jailbreak/prompt injection attacks and defenses
• Data/model extractiony
• Safety alignment, Red-team testing
• Large Models Memorization, Machine Unlearning
• Intellectual Property (IP) Protection of Models and Datasets
2. AI Safety.
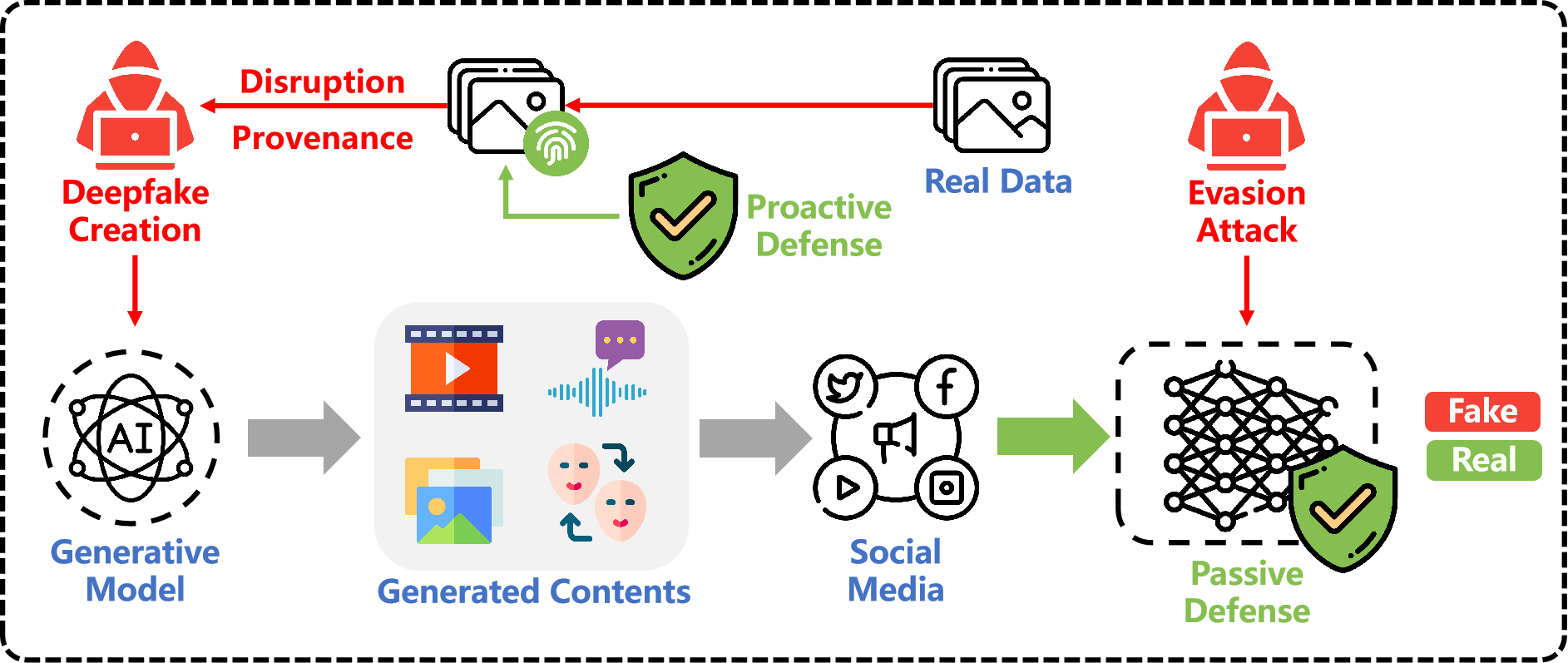
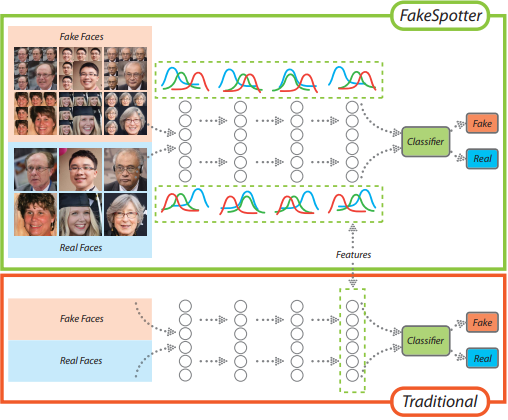
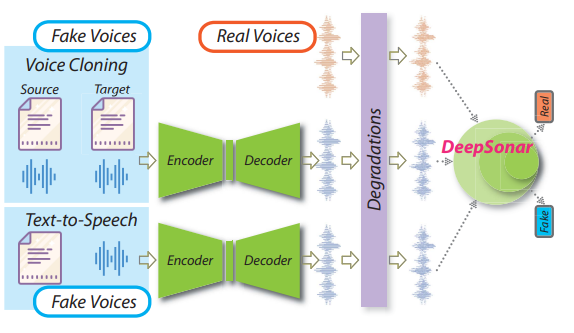
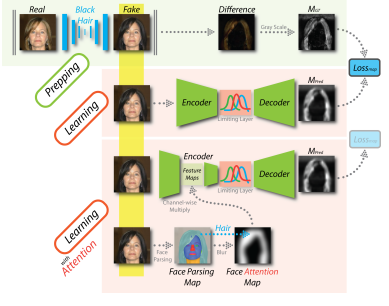
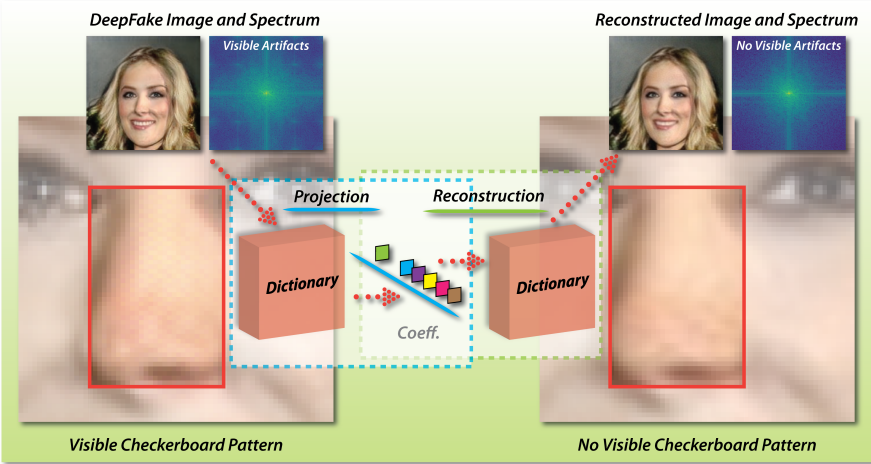
The emergence of AIGC (Artificial Intelligence Generated Content) has revolutionized the content creation landscape, enabling a multitude of applications across various industries. However, this rapid evolution has introduced critical challenges, including issues of content authenticity, ethical concerns, and the risk of generating misleading information, especially through deepfake technology. DeepFakes can create hyper-realistic audio and video content, raising significant risks such as misinformation and malicious uses. Our objective is to explore these challenges and develop frameworks for responsible AI-generated content. We are focusing on advanced generative models to assess their impact on content quality and investigate biases and misinformation. As AIGC, including DeepFakes, becomes more prevalent in marketing, journalism, and entertainment, addressing these concerns is vital for fostering trust and accountability in AI-driven content creation.
• DeepFake Passive Detection and Proactive Defense
• DeepFake Evasion Attack
• NSFW Attacks and Defenses
• Multimodal Learning, Vision-language Models
• Diffusion Models, Text2Image Generation, Text2Video Generation
3. AI for Security.
The rapid evolution of large language models (LLMs) has significantly transformed the cybersecurity landscape, creating new opportunities for dynamic and static analysis, as well as vulnerability discovery and exploitation. Our goal is to expand the use of LLMs in cybersecurity by developing intelligent framework for automated vulnerability detection and exploitation. Currently, we are enhancing dynamic analysis through advanced protocol fuzz testing, where LLMs generate diverse input data to simulate attack scenarios and uncover vulnerabilities. They also facilitate comprehensive code audits by automatically identifying security flaws like buffer overflows and injection vulnerabilities. Additionally, LLMs generate effective exploit code based on identified vulnerabilities, aiding security researchers in understanding these weaknesses and evaluating defense robustness. As these AI tools are increasingly adopted in safety-critical domains, it is crucial to address their limitations and improve their reliability to advance cybersecurity.
• LLM-assisted Program Analysis
• Vulnerability Discovery and Exploitation